
This map highlights the fact that a majority of content produced in Wikipedia is about a relatively small part of our planet. This finding supports previous work on the geographical biases of Wikipedia. Consider for example this visualization of the state of Wikipedia in 2010. We know that different language versions have varying shares of geocoded articles. English, Polish, German, Dutch and French are the Wikipedias with the largest numbers of geotagged articles. Since all these languages are spoken in Europe they may make a significant contribution to the dominant position of this continent in the above map.
By contrast, other continents are much less represented in the world’s most prominent digital repository of human knowledge. As we pointed out in the post about Africa on Wikipedia, the whole continent of Africa contains only about 2.6% of the world’s geotagged Wikipedia articles despite having 14% of the world’s population and 20% of the world’s land.
Further exploring the two groups represented in the map above (the inside and the outside of the red circle), we find that Wikipedia articles inside the circle have had a head start: they are on average a bit older than those outside. Especially in 2005 and 2006, editing activity about this European area picked up much faster than in the rest of the world.
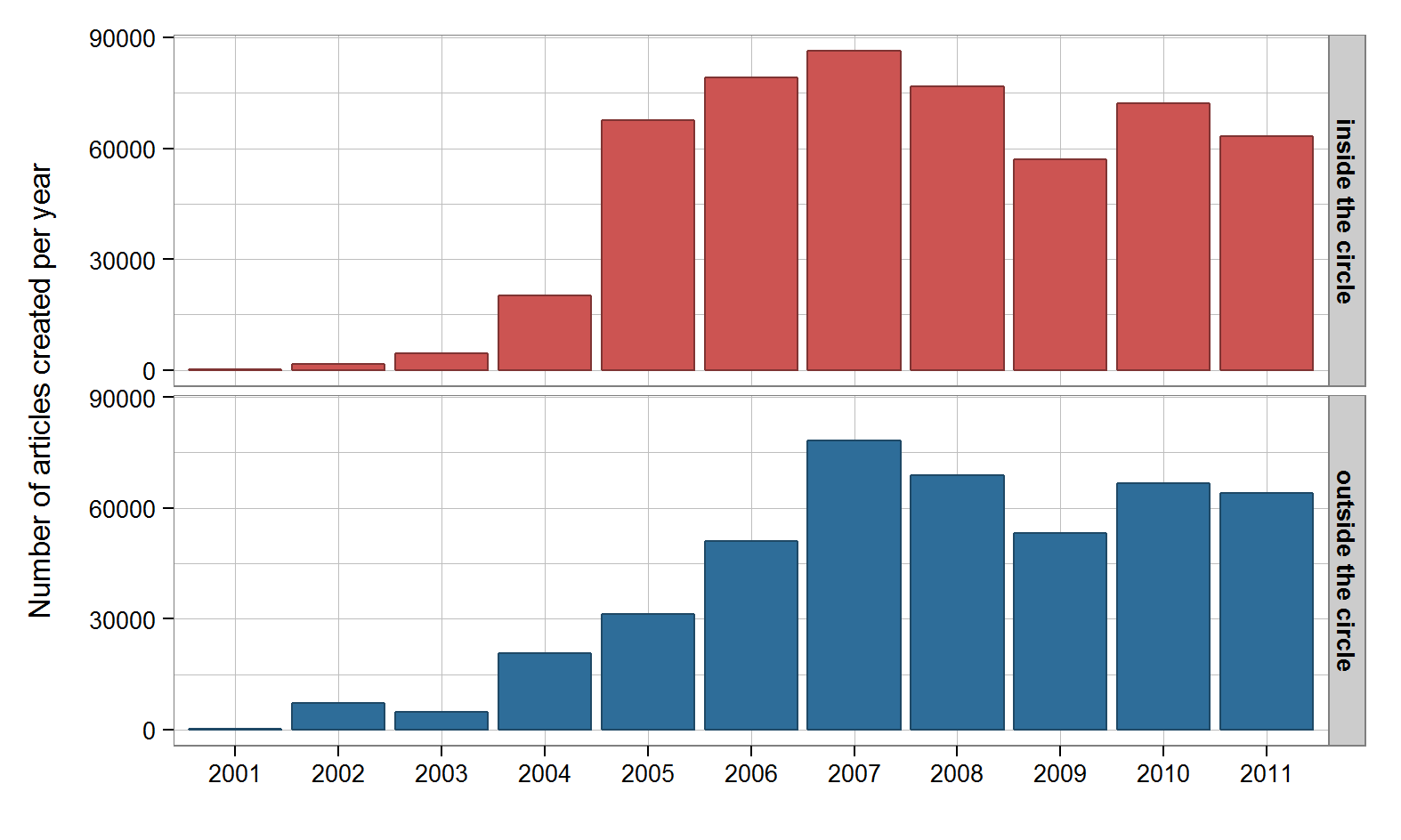
Wikipedia article age in different regions
Analysing the number of words per article shows that the articles inside the circle are a bit shorter than those outside. The average word counts per article are 419 inside the circle (median: 215) and 455 for the rest of the world (median: 260). To put this into perspective: these average word counts equate to the number of words you have read in this blog post up until this point.
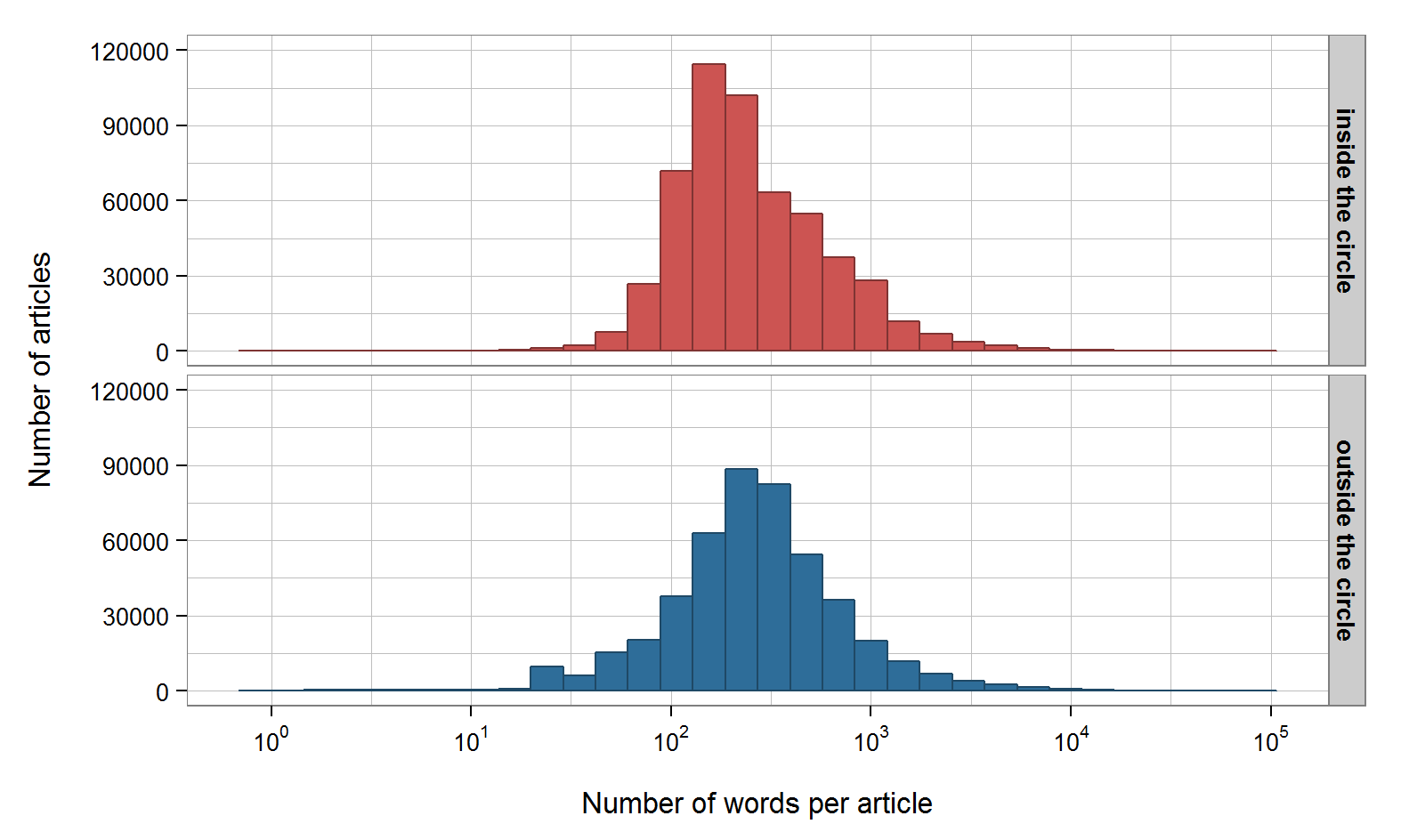
Wikipedia article length in different regions
While it is possible that this difference in word counts translates to differences in quality, one has to bear in mind that there may be other factors at play, such as variation in style and linguistic density or verbosity of the relevant languages in the respective areas.
However, at least within the English Wikipedia, we could show that in general word counts in large parts of Europe are indeed lower than those in North America. The comparison within Europe shows that articles about places, events and people in, for example, Italy and Great Britain are noticeably longer than those about such topics in France or Poland.
To obtain a clearer picture, we can analyse the distributions of languages, both inside and outside the circle. In doing so, we can clearly see that most major European languages (with the exception of English (EN), Russian (RU), and Spanish (ES)) have more articles inside the circle than outside.
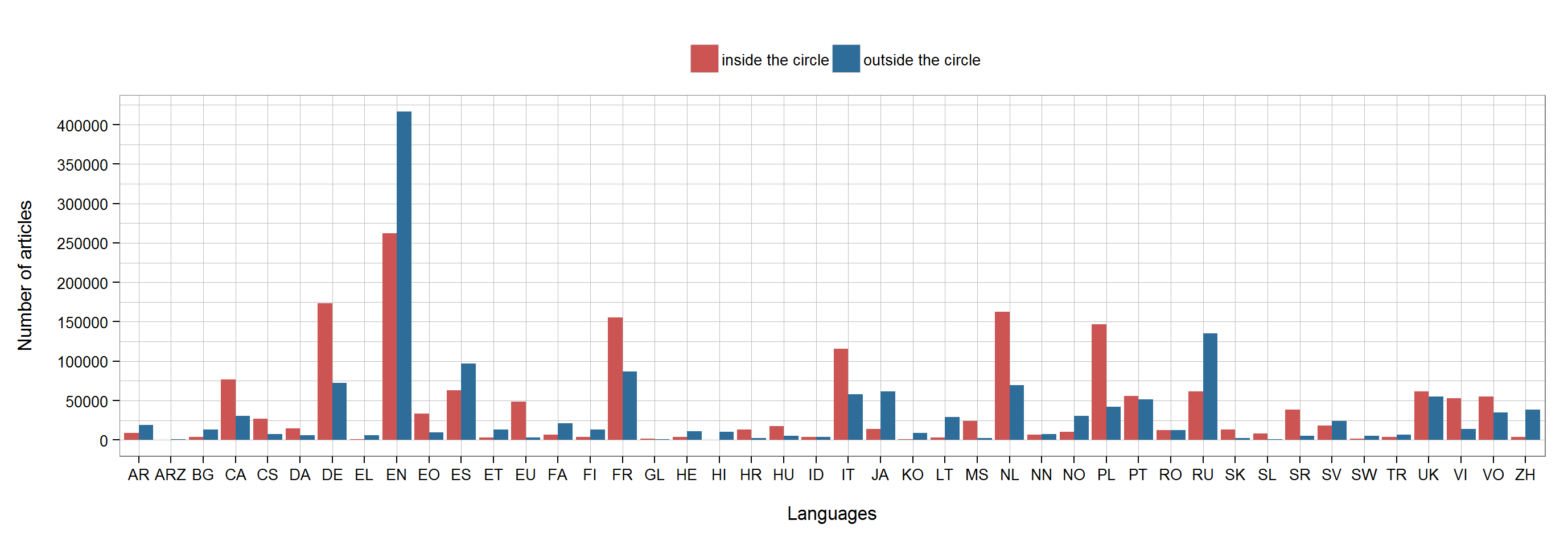
Wikipedia article numbers in different regions, per language
Thus, we could show a number of things: first, that the spatial distribution of Wikipedia articles is highly uneven at a global perspective. Second, that the average age as well as the average length of articles in Western and Central Europe (which constitute 50% of all articles) deviates somewhat from articles in the rest of the world. This stark dominance of content in the region is linked to both a strong overrepresentation of European languages and the often observed self-focus bias which states that people (and, similarly, it seems, language groups) edit Wikipedia mainly with respect to their surroundings.
This uneven distribution of knowledge carries with it the danger of spatial solipsism for the people who live inside one of Wikipedia’s focal regions. It also strongly underrepresents regions such as the Middle East and North Africa as well as Sub-Saharan Africa. In the global context of today’s digital knowledge economies, these digital absences are likely to have very material effects and consequences.
To read more about this work, you can download a forthcoming paper, in which Mark Graham, Bernie Hogan, Ralph Straumann and Ahmed Medhat have analysed these uneven patterns of representation in Wikipedia and their contributing factors. Currently, we are building on that work to analyse the equally uneven distribution of participation to Wikipedia.
Data
The map is based on Wikipedia data dumps encompassing 44 languages from November 2012. We excluded articles with more than four geotags, which typically consist of lists of geographic features. In the remaining data, we chose the most frequent geotag. If all geotags occurred only once, the first geotag (typically the most important one) was chosen as representative for the article. Additionally, we gathered article metrics such as number of characters and words in the article, the number of links to other Wikipedia articles, the number of external links and the number of in-article references. We mapped the article locations on top of a dataset that we obtained from Natural Earth using Buckminster Fuller’s Dymaxion map projection that has little distortion of shape and area and highlights that there is no ‘right way up’.
{kind=link}