Findings
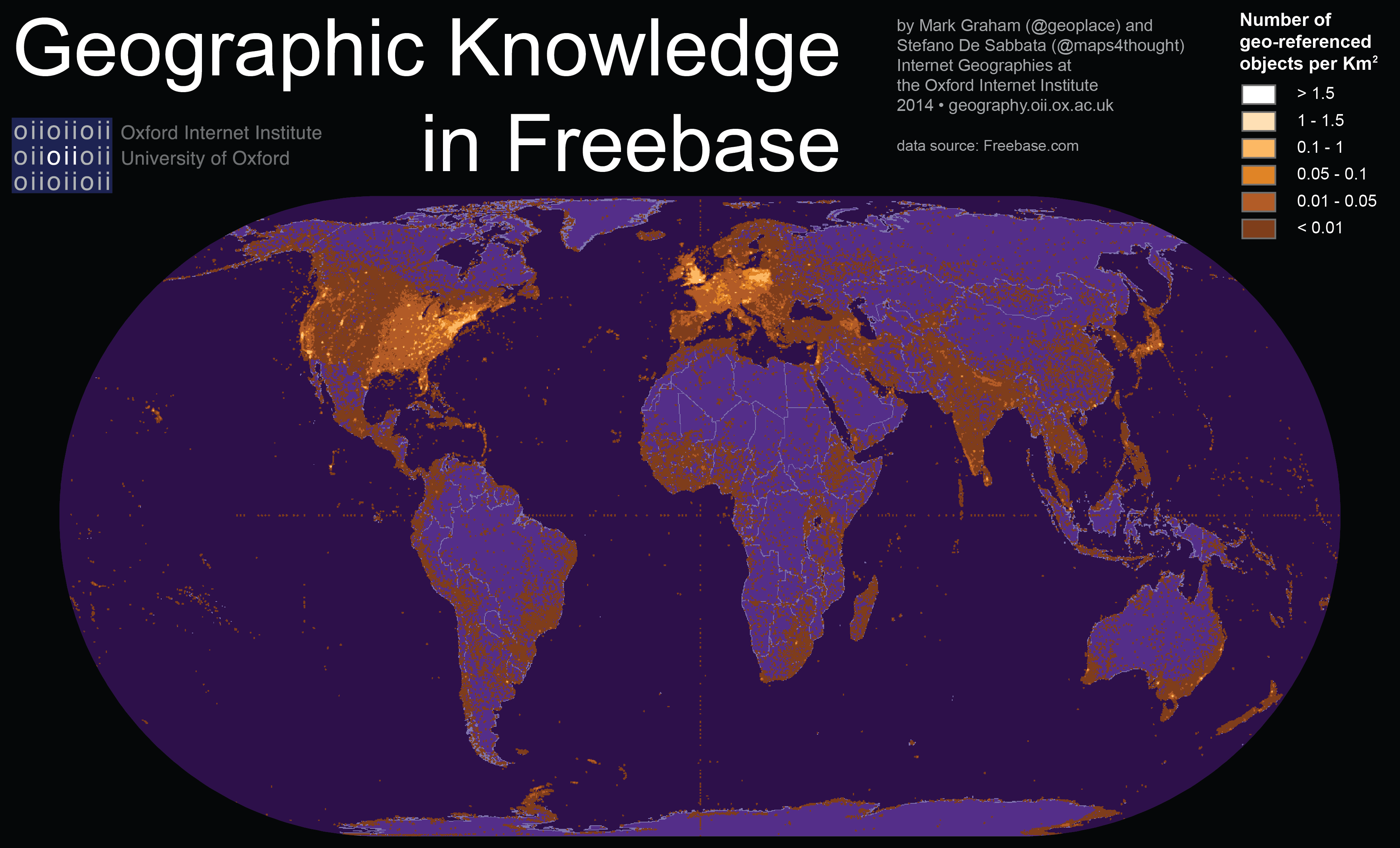
Geographic content in Freebase is largely clustered in certain regions of the world. The United States accounts for over 45% of the overall number of place names in the collection, despite covering about 2% of the Earth, less than 7% of the land surface, and less than 5% of the world population, and about 10% of Internet users. This results in a US density of one Freebase place name for every 1500 people, and far more place names referring to Massachusetts than referring to China.
A third of all place names are geo-located in Europe. The United Kingdom is home to about 7% of place names, Poland has about 6%, and France has just over 5%. The United Kingdom accounts for one place name for every 2000 inhabitants, the same proportion as Luxembourg. Ukraine is the only European country described with less than one place name per 30,000 inhabitants, whereas Slovenia and Poland are described in exceptional detail, with about one place name for every 1000 people and one place name for every 1300 inhabitants, respectively.
This stands in contrast to countries like China that account for less than 1% of the collection (with less than 4000 place names, and a density of only one place name for every 300,000 inhabitants). Most of Africa, Asia, Latin America and the Caribbean are similarly underrepresented. Nigeria barely represents 0.1% of the place names, and Venezuela accounts for only 0.05%. Outside Europe and North America, only four countries (Australia, China, India, and Japan) are represented with more content than Antarctica (in part because the database contains descriptions of hundreds of Antarctic mountains and ranges).
The largest cluster of under-represented countries is found in Sub-Saharan Africa, where only a handful of countries are described by more than one place name for every 100,000 inhabitants. South Africa is the notable exception, as it exhibits information counts comparable to most European countries. Other exceptions are Nepal and Bhutan in Asia, which score relatively highly compared to neighbouring countries. It is also worth pointing out that Indonesia in the country with the lowest information density in the world, with only one place name per 470,000 people.
Because Freebase is a core ingredient in the informational menu presented to us by the world’s most widely used search engine, these presences and absences have the potential to have a significant impact on how we understand, interact with, and create our world. Freebase may seem like a small corner of the Web, but the imbalances that we observe in it can have large reverberations through the broader information ecosystems accessed by billions of people.
Data
Freebase forms one of the key informational ingredients in Google’s Knowledge Graph. If you’ve ever looked at the side panel in Google’s search results page, which presents information about people, places, and events in response to a search query, then you’ve probably come into contact with data stored in Freebase.
The data that we collected from Freebase describe over 43 million entities, among which we identified 478 thousand place names. The content is stored as RDF triples, which specify a predicate in the form of subject-verb-object. The triples in the dataset have been surveyed, collecting all entities associated with a latitude-longitude coordinates pair; that is, all subjects of triples where the verb refers to the concept “has latitude” and “has longitude”.